Если вам интересна данная информация, то можете глянуть подобные статьи про видеоадаптеры AMD и втроенную графику от Intel, также вам может быть интересным:
Оглавление
С момента появления на рынке видеокарты NVIDIA GeForce GTX 480 прошло уже более двух лет. Это устройство было основано на чипе еще новейшей в то время архитектуры Fermi, которая была так названа в честь итальянского физика Энрико Ферми. Графические адаптеры на основе данной архитектуры были представлены в сентябре 2009 года и получили поддержку DirectX 11, которой у продуктов компании NVIDIA на тот момент не было. И хотя все это время архитектура Fermi активно развивалась, а на рынке появилось немало новых продуктов на ее основе, многие геймеры и специалисты ждали от калифорнийцев, по-настоящему новых решений.
Следует отметить, что темпы развития технологических процессов несколько приостановились, и мы были вынуждены довольно долго ждать от производителей появления нового поколения графических процессоров, созданных на базе более тонкого технологического процесса, тоньше, чем 40 нанометров. Первой выстрелила компания AMD, выпустив 28-наномеитровое топовое устройство уже в конце 2011 года, в то время, когда калифорнийская компания еще продолжала работать над своей новинкой.
И вот, 22 марта, компания NVIDIA продемонстрировала свою новейшую разработку, в очередной раз, названную в честь физика — Kepler. Сразу отметим, что в процессе разработки новейшей архитектуры основное внимание инженерами было уделено увеличению энергетической эффективности. Дело в том, что предыдущая архитектура – Fermi – оказалась очень быстрой, но при этом очень требовательной к энергии и соответственно горячей. Это объяснялось тем, что основной задачей в процессе разработки видеокарт на архитектуре Fermi было существенное увеличение производительности в сравнении с предыдущей архитектурой Tesla. При этом основной упор был сделан на ускорение обработки геометрии, универсальные вычислительные возможности и тесселяцию (метод разбиения полигонов на более мелкие части). Вопрос энергопотребления может и был важным параметром при разработке Fermi, но все же функциональность и производительность были куда важнее.
Одним из ключевых моментов в новой разработке является переход на 28 нм технологический процесс, который сыграл немаловажную роль в уменьшении энергопотребления, а технологические новшества в архитектуре Kepler повлияли на эффективность. Инженерами компании Nvidia были полностью переработаны все исполнительные блоки нового графического процессора.
Первое устройство на архитектуре Kepler
Первый вышедший на рынок процессор на новейшей архитектуре Kepler получил кодовое название GK104, а созданная на нем видеокарта — GeForce GTX 680. Как видно из названия GTX 680 — открывает новое семейство графических адаптеров NVIDIA с индексом 6, более производительных и эффективных своих предшественников, обладающих при этом меньшим показателем энергопотребления. Использование 28 нм технологического процесса позволило создать небольшой графический процессор с очень высокими показателями производительности. Однако больше всего на производительность повлияла полная переработка архитектуры графического процессора в целях оптимизации потребления энергии.

Компания NVIDIA проводит аналогию между своим новым устройством с гибридными автомобилями, которые обладают бензиновыми двигателями и электрическими моторами. Конечно, это не означает, что новинка обладает двумя различными ядрами, все дело в том, что видеокарта GTX 680 может потреблять минимум энергии и работать при этом в максимально производительном режиме. NVIDIA считает свой новый процессор не только самым быстрым из когда либо ею разработанных, но и самым эффективным решением по отношению к потреблению энергии.
Если быть точными, то архитектуру Kepler нельзя назвать новейшей в полном смысле слова. Она, скорее всего, является реорганизованным и пересмотренным вариантом архитектуры Fermi. Давайте посмотрим, что же нового принесла с собой Kepler, и какие перспективы в ближайшее время ждут всех поклонников современных компьютерных игр, а так же тех, кто активно работает с 3D-изображениями и видео контентом.
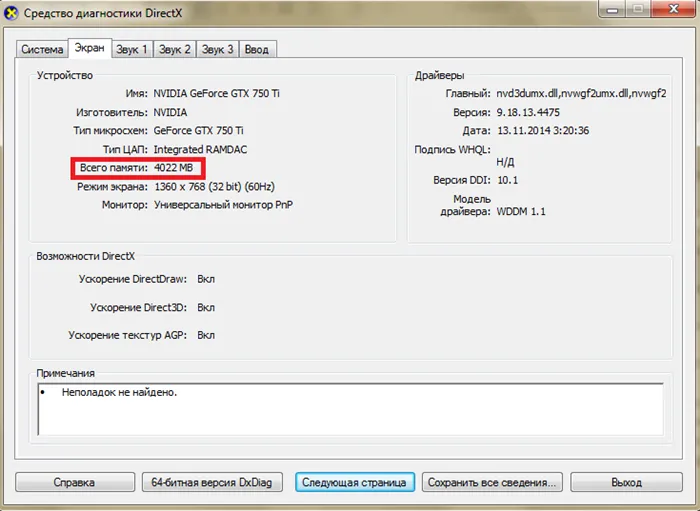
2014 год запомнился выходом новой 700 Series бюджетных видеeускорителей на архитектуре Максвелл. В частности, популярными стали две модели: видеокарты NVIDIA GEFORCE GTX 750 и 750 TI.
Линейки и маркировка видеокарт NVIDIA

Часто перед выбором сложно разобраться в ее позиционировании в линейке, а так же ее особенностях и производительности. Эта статья призвана осветить этот вопрос и рассказать вам об основных линейках видеокарт NVIDIA, их поколениях, предназначении, маркировке и производительности.
В данном материале не будут рассматриваться карточки до 2010 года выпуска и микроархитектуры Fermi, так как они уже потеряли свою актуальность на сегодняшний день. Исключения составляют лишь топовые для своего времени решения, но и они сейчас являются лишь простыми середнячками и нигде не продаются. Также здесь не будет рассмотрена линейка ION, ввиду того, что на данный момент компьютеры с данными карточками не продаются.
Для поиска полезной информации по видеокартам NVIDIA советуем воспользоваться их сайтом.
Если вам интересна данная информация, то можете глянуть подобные статьи про видеоадаптеры AMD и втроенную графику от Intel, также вам может быть интересным:
Линейки
GeForce
Это семейство является самым основным у компании NVIDIA. Ее представители ставятся как в мощные игровые ПК, так и в простенькие офисные ноутбуки. Видеокарты из этого семейства удовлетворяют 90% потребностей простых потребителей. Остальные семейства созданы для энтузиастов, для профессионалов и корпоративного сегмента или вовсе для достаточно необычных на первый взгляд задач.
Поколения
Поколение и микроархитектура видеочипа отражены в его кодовом названии. Так:
Про первые вышедшие карты на Pascal можете прочесть по соответствующим ссылкам: GTX 1060, GTX 1070, GTX 1080, TITAN X, а сейчас уже подоспели и мобильные GTX 1080/1070/1060.
Но в эту таблицу надо внести несколько поправок:
| Модели | Микроархитектура |
|---|---|
| 605 | Fermi |
| 610 | Fermi |
| 620 | Fermi |
| 630* | Fermi |
| 640* | Fermi |
| 645 | Fermi |
| 730* | Fermi |
| 750 | Maxwell |
| 750 Ti | Maxwell |
| 640M LE* | Fermi |
| 670M | Fermi |
| 675M | Fermi |
| 710M | Fermi |
| 720M | Fermi |
| 820M | Fermi |
| 870M | Kepler |
| 880M | Kepler |
| 920M | Kepler |
* — означает, что исключение существует для некоторых модификаций этих видеокарт.
- GT – это буквенное сочетание отражает видеокарты низкого уровня производительности, их нельзя рассматривать как игровые.
- GTX – этим индексом обозначаются видеоадаптеры среднего и высокого уровня, которые хорошо подходят для игр.
- M – мобильная видеокарта (они сильно слабее своих братьев без этой буквы)
- X – маркировка более производительной видеокарты у мобильных решений
- LE – так обозначается версия карты с более низкой тактовой частотой у мобильных адаптеров
- Ti – обозначение более производительной версии у десктопных карт
Стоит отметить, что более производительная версия отличается не только разгоном, но и компонентами ядра (унифицированные шейдерные блоки, блоки текстурирования, блоки растеризации).
Возможно, начиная с поколения Pascal мобильные видеокарты перестанут оснащаться буквой M, так как используют почти те же чипы.
Следующие после поколения цифры указывают на положение модели в линейке.
Интересный факт: 90 означает 2 чипа 80 в режиме SLI (работают в паре).
TITAN
Это подлинейка GeForce, ведь они имеют индекс GTX. Для начала надо разобраться с позиционированием данной линейки. Это самые быстрые и дорогие видеокарты на данный момент. Но эта цена действительно слишком высока для такого уровня производительности. Все дело в том, что так же они позиционируются, как мощные профессиональные видеокарты для математических вычислений и вычислений FP 64 (вычисления с плавающей запятой двойной точности). Это своего рода внедорожник в мире видеокарт – и работать можно и играть. Исключением является Titan X, который не хватает с неба звезд в FP 64 – вычислениях и по сути является просто очень дорогой видеокартой с огромным набором видеопамяти.
В этой линейке на начало 2016 года есть только 5 видеокарт и почти все в референсном дизайне (версии от сторонних производителей).
Оба демо задали первоначальный вектор презентации – NVIDIA Kepler оказалась не просто более производительной, а еще и более энергоэффективной архитектурой. А это значит не просто банальную экономию энергии, а и меньшее тепловыделение и шум в десктопах, а также большую автономность в ноутбуках.
Архитектура NVIDIA Tesla
NVIDIA решила проблему увеличения сложности с помощью своей первой «унифицированной» архитектуры Tesla в 2006 году. умереть G80 был больше нет различий между слоями. Потоковые мультипроцессоры (SM) заменили все предыдущие диски благодаря их способности выполнять обработку вершин, генерацию сегментов и соединение сегментов без различия в одном ядре. Таким образом, кроме того, нагрузка автоматически уравновешивается путем обмена «ядер», выполняемых каждым SM, в зависимости от потребностей каждого момента.
Таким образом, шейдерные блоки теперь являются «ядрами» (больше не совместимыми с SIMD), которые способны самостоятельно обрабатывать целочисленные инструкции или инструкции с плавающей запятой (SM получают потоки группами по 32 потока, называемыми деформациями). В идеале все потоки в деформации будут выполнять один и тот же оператор одновременно только с разными данными (отсюда и название SIMT). Блок многопоточных (MT) инструкций отвечает за включение и отключение потоков на каждой деформации в случае, если указатели инструкций (IP) сходятся или различаются.
Две СФУ единицы (вы можете увидеть их на диаграмме выше) отвечают за сложные математические вычисления, такие как обратные квадратные корни, синусы, косинусы, exp и rcp. Эти блоки также способны выполнять одну инструкцию для каждого тактового цикла, но поскольку их всего две, скорость выполнения делится на четыре для каждого из них (то есть для каждого четырех ядер используется один SFU). Аппаратная поддержка вычислений float64 отсутствует, и они выполняются программно, что значительно снижает производительность.
SM работает с максимальным потенциалом, когда задержку памяти можно устранить, всегда имея программируемые деформации в очереди выполнения, но также и тогда, когда поток деформации не имеет расхождений (это то, для чего нужен поток управления, который поддерживает их всегда в одном и том же путь инструкций). Файл журнала ( 4KB РФ ), где хранятся состояния потоков, а потоки, которые потребляют слишком много очереди выполнения, уменьшают количество их в этом журнале, что также снижает производительность.
«Флагманским» кристаллом этой архитектуры NVIDIA Tesla был G90, основанный на 90-нанометровом литографическом процессе, представленный в знаменитой GeForce 8800 GTX. Два SM сгруппированы в кластер текстурного процессора (TPC) вместе с текстурным блоком и кешем Tex L1. С 8 TPC у G80 было 128 ядер, генерирующих полную мощность 345.6 Гфлопс. GeForce 8800 GTX в то время пользовалась огромной популярностью.
С архитектурой Tesla NVIDIA также представила язык программирования CUDA (Compute Unified Devide Architecture) в C, расширенный набор C99, который был долгожданным облегчением для энтузиастов GPGPU, которые приветствовали альтернативу обмануть GPU с помощью шейдеров и текстур GLSL.
Хотя в этом разделе основное внимание уделялось SM, они составляли лишь половину системы. SM должны получать инструкции и данные, находящиеся в графической памяти графического процессора, поэтому, чтобы избежать застоя, графические процессоры не избегают «отключений» памяти с большим количеством кэш-памяти, как это делают процессоры (ЦП), а, скорее, они загромождают память bus для запросов ввода / вывода от тысяч управляемых потоков. Для этого в микросхеме G80 была реализована высокая производительность памяти через шесть двунаправленных каналов памяти DRAM.
Архитектура Ферми
Тесла был очень рискованным шагом, но он оказался очень хорошим, и он был настолько успешным, что стал основой архитектур NVIDIA на следующие два десятилетия. В 2010 году NVIDIA выпустила GF100 умереть на основе нового ферми архитектура, с многочисленными новыми функциями внутри.
Модель исполнения все еще вращается вокруг 32-проводных деформаций, запрограммированных в SM, и это было только благодаря 40нм литография (по сравнению с 90-нм техпроцессом Tesla), что NVIDIA почти все увеличила в четыре раза. SM теперь может программировать два медиа-деформирования (16 потоков) одновременно благодаря двум наборам из 16 ядер CUDA. Когда каждое ядро выполняло одну инструкцию за такт, один SM смог выполнить одну инструкцию деформации за цикл (а это в 4 раза больше, чем у Tesla SM).
Счетчик SFU также был усилен, хотя и в меньшей степени, потому что он «просто» умножился на два, всего четыре единицы. Также была добавлена аппаратная поддержка вычислений float64, которых не хватало Tesla, выполняемых двумя объединенными ядрами CUDA. GF100 может выполнять целочисленное умножение за один такт благодаря 32-битному ALU (по сравнению с 24-битным в Tesla) и имеет более высокую точность с плавающей запятой.
С точки зрения программирования, унифицированная система памяти Fermi позволила расширить CUDA C такими функциями C ++, как виртуальные объекты и методы.
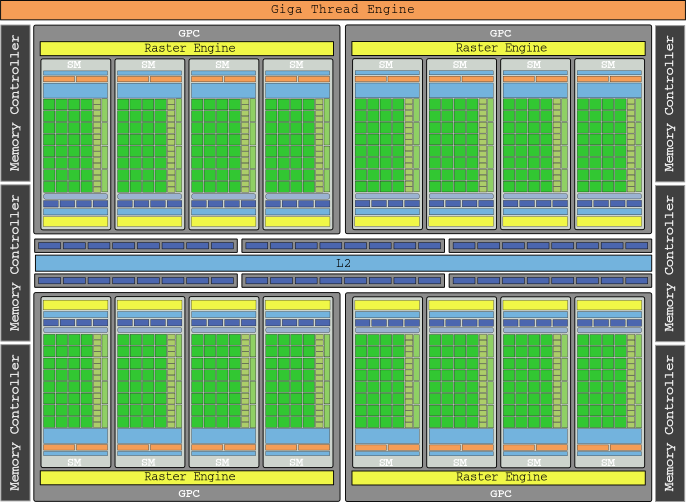
Поскольку текстурные блоки теперь являются частью SM, понятие TPC исчезло, его заменили кластеры графического процессора (GPC), которые имеют четыре SM. И наконец, что не менее важно, был добавлен механизм «Полиморфа» для обработки вершин объектов, преобразования представления и тесселяции. Графическим флагманом этого поколения была GTX 480 с 512 ядрами, полная мощность которой составляла 1,345 Гфлопс.
Вершина линейки графиков этого поколения — RTX 2080 Ti с его кристаллом TU102 и 68 TSM, содержащим 4352 ядра, с общей мощностью 13.45 TFLOP. Мы не помещаем его полную блок-диаграмму, как в предыдущих, потому что для того, чтобы она поместилась на экране, ее пришлось бы сжать настолько сильно, что это стало бы размытием.
NVIDIA GeForce GT 640M
На сегодняшний день ультрабуки являются наиболее трендовой темой мобильного рынка наравне с планшетами и смартфонами. При этом казуальные пользователи обычно не обращают внимания на то, что это не просто красивый термин, а торговая марка компании Intel, которая вправе определять список необходимых для попадания в данный класс требований.
Интересно, что до анонса архитектуры NVIDIA Kepler в список таких условий не входило обязательное отсутствие в ультрабуках дискретной видеокарты. Остальные требования, как то минимальная толщина корпуса и максимально возможная автономность подразумевали, что производительным графическим решениям в этом классе не место, но формального запрета от Intel не было. Как оказалось, мобильная версия NVIDIA Kepler обладает настолько умеренным энергопотреблением, что ультрабук с дискретной видеокартой стал реальностью. Первой свое решение представила компания Acer, чья модель Aspire Timeline U M3 основана на связке процессора Intel Core i5-2467M и графикой NVIDIA GeForce GT 640M.

Эта среднеформатная модель, заключенная в сверхтонкий корпус толщиной всего 2 см способна отработать до 8 часов в офисном режиме и при этом способна обеспечить комфортный уровень производительности в совремемнных игровых проектах.

При этом модель Acer Aspire Timeline Ultra M3 обеспечивает тот же уровень игровой производительности, которым могли похвастать намного более габаритные и увесистые решения прошлых лет на основе GTX 460M и GTX 285M.

Компания NVIDIA особо отметила, что GeForce 600M вдвое производительнее видеокарт предыдущего поколения 500M и до 10 раз быстрее актуальных интегрированных графических решений.

Показательно, что даже решение начального уровня, NVIDIA GeForce GT 620M обеспечивает играбельный fps в ряде современных игровых проектов.
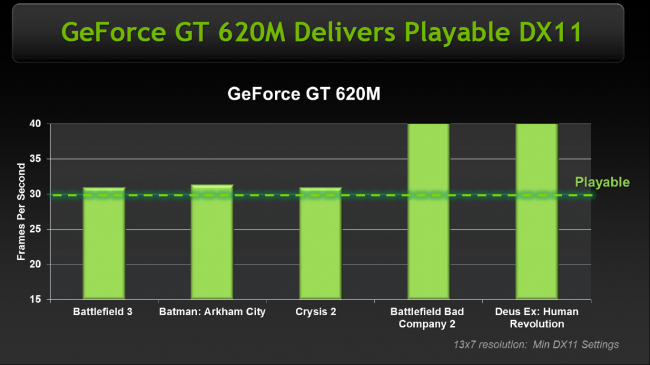
При том же уровне производительности, графика GeForce 600M потребляет вдвое меньше энергии, что особенно важно в случае использования в сверхтонких ультрабуках, которые не могут позволить себе использовать громоздкую систему охлаждения.

Команды и данные, которые поставляются на GPU, могут быть взаимозависимыми (например, если расчеты зависят от результатов других вычислений), таким образом, части разных потоков могут блокироваться от выполнения на GPU некоторый промежуток времени. NVIDIA постаралась внести и улучшения обработки подобных ситуаций в интерфейс CUDA.
Планировщик инструкций (Instruction Scheduling)
Чтобы отдельные шейдеры работали эффективно, NVIDIA внесла некоторые изменения в сферах балансировки нагрузки (Workload Balancing), Clock-Gating Granularity, планировании инструкций (Instruction Scheduling) и количестве исполняемых инструкций за такт (Instructions Issued per Clock Cycle). Последний параметр не изменился по сравнению с «Fermi» и «Kepler», но NVIDIA снизила задержки для повышения эффективности. Улучшения балансировки нагрузки также связаны и с разделением warp-планировщиков. На каждый кластер SMM по-прежнему используется четыре warp-планировщика (Warp Scheduler)», как и в кластерах SMX архитектуры «Kepler», но четыре warp-планировщика больше не являются общими для всех потоковых процессоров, а работают только со своей группой ядер CUDA (они адаптированы по ширине к warp-планировщику). Кроме того, warp-планировщик может по-прежнему в один такт (dual-issue) распределять математические операции на потоковые процессоры, а также операции работы с памятью на блоки «Load / Store units». Впрочем, и в режиме single-issue warp-планировщик может полностью нагружать потоковые процессоры.
Оптимизации, приведенные выше, связаны с аппаратным обеспечением. Но плохой код может и не раскрыть преимуществ архитектуры. Исходя из предположения, что существующий код меняться не будет, NVIDIA внесла улучшения в регистры. Между архитектурами «Maxwell» и «Kepler» не произошло изменений по числу 64K 32-битных регистров на SMM/SMX, 64 warp и, максимум, 255 регистров на поток. Удвоилось количество активных потоковых блоков на потоковый мультипроцессор SMM до 32. От этого шага можно ожидать повышения эффективности нагрузки.
Выделенная общая память
У архитектур «Maxwell» и «Kepler» предусмотрено 64 кбайт общей памяти. Но у «Kepler» она разделяется 48/16 кбайт между кэшем L1 и общей для кластера памятью. У «Maxwell» кэш L1 и текстурный кэш объединены, ограничение на потоковый блок по-прежнему составляет 48 кбайт, но повышение объёма общей памяти должно привести к улучшению эффективности.
| Сравнение архитектур «Kepler» и «Maxwell» | ||
|---|---|---|
| GPU | GK107 | GM107 |
| Максимальное количество потоковых процессоров | 384 | 640 |
| Базовая частота | 1.058 МГц | 1.020 МГц |
| Частота Boost | — | 1.085 МГц |
| GFLOPs | 812,5 | 1305,6 |
| Вычислительный интерфейс | 3.0 | 5.0 |
| Shared Memory / SM | 16 kB / 48 kB | 64 kB |
| Register File Size | 256 kB | 256 kB |
| Active Blocks / SM | 16 | 32 |
| Текстурные блоки | 32 | 40 |
| Текстурная скорость заполнения | 33,9 Гтексель/с | 40,8 Гтексель/с |
| Частота памяти | 1.250 МГц | 1.350 МГц |
| Пропускная способность | 80 Гбайт/с | 86,4 Гбайт/с |
| ROPs | 16 | 16 |
| Объём кэша L2 | 256 кбайт | 2.048 кбайт |
| Количество транзисторов | 1,3 млрд. | 1,87 млрд. |
| Площадь кристалла | 118 мм 2 | 148 мм 2 |
| Техпроцесс | 28 нм | 28 нм |
| TDP | 64 Вт | 60 Вт |
Чтобы эффективно использовать общую память у «Maxwell» применяются так называемые атомарные операции для 32-битных целочисленных вычислений, а также операции «Native Shared Memory 32 Bit and 64 Bit compare-and-swap (CAS)». В случае «Kepler» и «Fermi» приходилось использовать сложный принцип «Lock/Update/Unlock», что приводило к дополнительным издержкам.
Видеокарты NVIDIA GEFORCE GTX 660 в 2012 году навели много фурору по поводу своих возможностей и приемлемой цены в продаваемом тогда коридоре 200-250$.
GTX 1660

Видеокарта NVIDIA GEFORCE GTX 1660 SUPER – улучшенная версия ранее выпускаемой 1660. Как и в младшей версии из 1600 серии здесь нет реализации тензорных и RT-ядер. Но, они реализованы на достижение наилучшего качества при наименьших затратах энергии, и задействовании самой последней Turing-архитектуры с техпроцессом в 12 нм.
| Тех. хар-ки | |
| Арх. | TU116 |
| Размер транз-ров | 12 нм |
| Такт. част. GPU | 1530-1785 МГц |
| Шейдерные блоки | 1408 |
| TMU | 88 |
| ROP | 48 |
| Шина memory | 128 бит |
| Тип memory | GDDR6, 6 ГБ |
| Frequency | 14000 МГц |
| API | DirectX 12.1 (FL) |
| TDP | 125, Вт |
Карточку можно считать эконом вариантом без навортов на обновленном железе. Она лучше на 20-40% младшей версии (модифицированной), с возможностью малых энергозатрат она реализуется под домашние задачи и умеренный гейминг ново вышедших игр любой направленности.
GTX (RTX) 2060

В 2019 году NVIDIA запускает линейку 2000 серии и преобразует название с GTX на RTX. При этом, стартует новая линейка на архитектуре Turing, что приносит еще большие инновации в мир графики.
Особенно нашумевшей стала технология трассировки лучей, которую наконец-то NVIDIA смогла реализовать в играх. Трассировка лучей — это технология построения трехмерных моделей, с использованием принципа по аналогии с настоящими физическими процессами.
Технология довольно старая (заговорили о ней еще в восьмидесятые), и ранее уже предоставлялась в гибридном виде. Но ранее это было не совсем то, что наблюдается сейчас.
| Тех. хар-ки | |
| Арх. | TU106 |
| Размер транз-ров | 12 нм |
| Кол-во транз-ров | 10,8 млрд. |
| Шейдерные блоки | 1920 шт. |
| TMU | 120 шт. |
| ROP | 48 шт |
| База / динамика (частота) | 1365 / 1680 МГц |
| Пропуск. Способн. | 336 ГБ/с |
| Шина memory | 192бит |
| Тип memory | GDDR6, 6 ГБ |
| Frequency | 14000 МГц |
| API | DirectX 12.1 (FL) |
| TDP | 160 Вт |
Видеокарта NVIDIA GEFORCE RTX 2060 традиционно по стопам GTX 1060 продолжает привносить новшества архитектуры Turing и мир 3D. Карты достаточно с лихвой для игр, поддерживающих трассировку лучей в 4K со стабильными 25-30 FPS. В тот же Батлфилд V можно погонять без проблем. Также, RTX 2060 – это отличный вариант за «не дорого» получить возможность все новшества Turing и реализовать их в PC-Gaming.
За десятилетие NVIDIA значительно продвинулась как компания, выпускающая продукты, меняющие и преобразующие 3D-графику от архитектуры к архитектуре. Это наблюдалось в каждой серии видеокарт GTX до 2020 включительно. Хочется пожелать, чтобы RTX и последующие названия графических карт на новой архитектуре, совершенствовали взаимодействие с 3D-графикой привнося в них действительно революционные новшества.