Часто задаваемые вопросы о видеокартах GeForce: что нужно знать о видеокартах?
FAQ по видеокартам GeForce: что следует знать о графических картах?
Ядро CUDA, потоковый процессор и шейдерный блок — все это синонимы вычислительного блока графического процессора, который выполняет вычисление данных. NVIDIA традиционно называет их ядрами CUDA, где CUDA означает Compute Unified Device Architecture. Ядра CUDA отличаются от ядер процессора, намного менее сложны и имеют высокую степень специализации для обрабатываемых данных. Сегодня графические процессоры могут делать гораздо больше, чем просто отрисовывать графику через конвейер, поэтому объединение под названиями унифицированного потокового процессора или шейдерного блока вполне разумно.
Потоковый процессор обрабатывает непрерывный поток данных, которых много сотен, и работает параллельно на многих потоковых процессорах. Современные графические процессоры оснащены несколькими тысячами потоковых процессоров и отлично подходят для высокопараллельных задач. Это и графический рендеринг, и научные расчеты. Это, среди прочего, позволило графическим процессорам закрепиться в серверном сегменте в качестве вычислительных ускорителей.

Однако потоковые процессоры — довольно общий термин; на практике современные графические процессоры более сложны. Графические процессоры могут выполнять вычисления с плавающей запятой (FP) и целочисленные (INT) с различной точностью. Для графики наиболее важными вычислениями являются FP32 и INT32 с 32-битной точностью. В случае научных расчетов все большее значение приобретают вычисления с большей точностью, то есть FP64. Поэтому в графическом процессоре есть выделенные вычислительные блоки для типа данных FP64. Однако не все вычисления требуют 32- и 64-битной точности. Были разработаны методы для выполнения менее точных вычислений с блоками INT32, таких как одновременное выполнение операций с двумя 16-разрядными целыми числами.
Еще одним прорывом можно назвать интеграцию ядер Tensor в архитектуру NVIDIA Volta и Turing, которые способны эффективно вычислять менее сложные числа INT8 и INT4, но об этом позже.
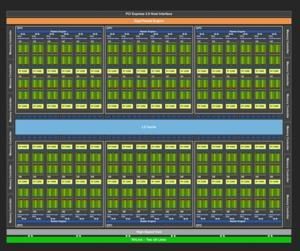
Мы рассмотрим структуру вычислительных блоков на основе архитектуры Тьюринга, которые организованы в определенные структуры. Графический процессор TU102 имеет шесть кластеров обработки графики (GPC), 36 кластеров обработки текстур (TPC) и 72 потоковых мультипроцессора (SM). Но на GPU видеокарты GeForce RTX 2080 Ti активны только 34 TPC. Каждый GPC содержит шесть TPC, каждый TPC содержит два потоковых мультипроцессора SM. Последние предлагают 64 потоковых процессора, поэтому 34 потоковых процессора TPC x 2 SM x 64 обеспечивают ровно 4352 потоковых процессора на видеокарте GeForce RTX 2080 Ti.
NVIDIA масштабирует архитектуру Turing с GeForce RTX 2060 до GeForce RTX 2080 Ti. Ниже представлен обзор видеокарт GeForce RTX:
| Шаблон | GeForce RTX 2080 Ti | GeForce RTX 2080 | GeForce RTX 2070 | GeForce RTX 2060 |
| Цена | от 72,600 ₽ | от 47 000 | от 31 500 | с 21.100 |
| Технические характеристики | ||||
|---|---|---|---|---|
| Архитектура | Тьюринг | Тьюринг | Тьюринг | Тьюринг |
| GPU | ТУ102 | ТУ104 | ТУ106 | ТУ106 |
| Технический процесс | TSMC 12 нм | TSMC 12 нм | TSMC 12 нм | TSMC 12 нм |
| Количество транзисторов | 18,6 миллиарда | 13,6 миллиарда | 10,8 миллиарда | 10,8 миллиарда |
| Хрустальная область | 754 мм² | 545 мм² | 445 мм² | 445 мм² |
| Потоковые процессоры | 4 352 | 2 944 | 2,304 | 1,920 |
| Тензорные ядра | 544 | 368 | 288 | 240 |
| Ядро RT | 68 | 46 | 36 | тридцать |
| Блоки утка | 272 | 184 | 144 | 120 |
| Геометрические блоки | 34 | 23 | 18 | 15 |
| ROP | 88 | 64 | 64 | 42 |
| Частота GPU (базовая) | 1350 МГц | 1.515 МГц | 1410 МГц | 1365 МГц |
| Частота GPU (Boost) | 1,635 МГц | 1800 МГц | 1710 МГц | 1680 МГц |
| RTX-OPS | 78 TRTX-OPS | 60 TRTX-OPS | 45 TRTX-OPS | 37 TRTX-OPS |
| Гигалучей / с | 10 сбоев / с | 8 сбоев / с | 6 Глуч / с | 5 сбоев / с |
| Частота памяти | 1750 МГц | 1750 МГц | 1750 МГц | 1750 МГц |
| Тип памяти | GDDR6 | GDDR6 | GDDR6 | GDDR6 |
| Объем памяти | 11 ГБ | 8 ГБ | 8 ГБ | 6 ГБ |
| Ширина шины памяти | 352 бит | 256 бит | 256 бит | 192 бит |
| Пропускная способность | 616 ГБ / сек | 448 ГБ / сек | 448 ГБ / сек | 336 ГБ / сек |
| TDP | 260 Вт | 225 Вт | 185 Вт | 160 Вт |
| Добавить питание | 2x 8-контактный | 1x 8 контактов + 1x 6 контактов | 1x 8-контактный | 1x 8-контактный |
| SLI / NVLink | 2x NVLink | 1x NVLink | — | — |
на рынок также была представлена видеокарта Titan RTX, основанная на полной версии графического процессора TU102. NVIDIA продает Titan RTX как «Ultimate PC GPU», графическую карту, предназначенную для исследователей, ученых и разработчиков в области глубокого обучения и искусственного интеллекта. Полная версия TU102 GPU оснащена шестью кластерами графической обработки (GPC), 36 TPC (кластерами обработки текстур) и 72 потоковыми мультипроцессорами (SM). В случае Titan RTX у нас 4608 потоковых процессоров, 576 ядер Tensor и 96 ядер RT. Полная конфигурация памяти составляет 384 бита, NVIDIA подключает 12 микросхем памяти GDDR6. В случае с Titan RTX NVIDIA использует микросхемы памяти Samsung на 2 ГБ, которые предлагают до 24 ГБ памяти.





Одновременные операции с целыми числами и числами с плавающей запятой
Как уже было сказано, вычислительные блоки FP32 могут работать в режиме 2x FP16, то же самое и для INT16. Чтобы повысить производительность обработки и сделать ее более гибкой, архитектура NVIDIA Turing предоставляет возможность одновременно вычислять числа с плавающей запятой и целые числа. NVIDIA проанализировала эти вычисления конвейера рендеринга в десятках игр и обнаружила, что на каждые 100 вычислений FP приходится около трети вычислений INT. Однако значение среднее, на практике оно колеблется от 20% до 50%. Конечно, если вычисления FP и INT выполняются одновременно, иногда конвейер должен «замедляться» в случае соединений.

Во всех предыдущих архитектурах NVIDIA одновременные вычисления целых чисел и чисел с плавающей запятой не поддерживались. В случае Тьюринга все изменилось. Параллельная обработка FP и INT ускоряет рендеринг, поэтому NVIDIA просто добавила его в архитектуру Turing. Turing SM имеет 64 блока FP32 и 64 блока INT32, что не совсем типично для конвейера рендеринга. Но одновременная работа блоков позволила значительно увеличить вычислительную производительность.
Потоковые процессоры давно превратились в вычислительные блоки общего назначения в графических процессорах. Конечные вычислительные характеристики зависят от их количества, но здесь следует учитывать точность расчетов.
Текстурные блоки
Потоковые процессоры выполняют так называемые шейдеры, которые представляют собой небольшие программы. Вершинные шейдеры используются для геометрических вычислений и динамически изменяющихся объектов. Шейдеры геометрии позволяют рассчитать окончательную геометрию и структуру объекта по точкам, линиям и треугольникам. Шейдеры тесселяции обеспечивают дальнейшее разделение примитивов (тех же треугольников).
Блоки наложения текстур (TMU) отвечают за обеспечение того, чтобы все поверхности были покрыты соответствующими текстурами. TMU — это специализированные арифметические блоки графического процессора. В случае архитектуры Тьюринга текстурный блок объединяет 16 потоковых процессоров. Данные для блоков кадров хранятся в видеопамяти и могут считываться и записываться оттуда. Поскольку блоки TMU больше не являются полностью внешними арифметическими блоками, а интегрированы в конвейер рендеринга, каждый блок текстуры может обрабатывать объекты несколько раз. Фактически, простых текстур уже недостаточно для рендеринга объекта; использование нескольких слоев приводит к созданию трехмерного изображения, а не плоской текстуры. Раньше объекты приходилось вычислять несколько раз, и каждый раз, когда блок текстуры применял текстуру, сегодня достаточно обычного процесса рендеринга, блок текстуры может получать данные для многократной обработки из буфера.
Контроллер памяти
Высокая пропускная способность памяти так же важна, как и производительность обработки графического процессора. Только если данные могут быть быстро считаны из видеопамяти в графический процессор и перезаписаны, вычисления будут выполняться достаточно быстро. С одной стороны, есть графический процессор, который выполняет вычисления, а с другой — система кеширования и памяти. Архитектура графического процессора предназначена для использования преимуществ высокой пропускной способности памяти. Производители стараются выжать максимум из подсистемы памяти, поэтому контроллер памяти имеет решающее значение.
Начиная с архитектуры Pascal, NVIDIA придерживается почти идентичной структуры графического процессора для работы с памятью GDDR. Интерфейс памяти разделен на 32-битные блоки. В полной версии NVIDIA предоставляет ширину шины 384 бита, но из-за отключенного 32-битного блока мы получаем от GeForce RTX 2080 Ti 352 бита. Микросхема памяти подключается через каждый 32-битный интерфейс. 352 бит / 32 бит обеспечивает 11 каналов и 11 микросхем памяти GDDR6. В случае GeForce RTX 2080 и GeForce RTX 2070 ширина шины ограничена 256 битами, что составляет восемь каналов и восемь микросхем памяти GDDR6.
Ядра Tensor и RT
Тензорные ядра
В архитектуре Тьюринга NVIDIA представила два новых вычислительных блока, ранее не использовавшихся в графических процессорах. Конечно, ядра Tensor знакомы нам по архитектуре Volta, но там они использовались для научных расчетов. В случае графических процессоров Turing и видеокарт GeForce RTX эти блоки играют особую роль.
Тензорные ядра предназначены для умножения матриц. Умножение матриц (BLAS GEMM) является наиболее важным компонентом для обучения и вывода сетей глубокого обучения. Операции с матрицами включают получение значений матриц A и B (путем сложения и умножения), после чего результат будет записан в матрицу C. Для матриц 4×4 эти операции выполняются для всех 16 полей. В архитектуре Pascal для выполнения этих операций использовались блоки FP32, поэтому скорость оставляла желать лучшего.
Тензорные ядра в архитектуре Тьюринга могут запускать INT16, INT8 и INT4. Вычислительная производительность INT8 вдвое выше, чем у INT16, так как можно выполнять две операции INT8 вместо INT16. То же верно и для сравнения INT4 и INT8. В большинстве графических процессоров TU102 NVIDIA перечисляет 576 тензорных ядер. Но с GeForce RTX 2080 мы получаем только 544 тензорных ядра, для которых NVIDIA указывает вычислительную производительность 110 TFLOPS FP16 для игр и обработки изображений. В случае вычислений INT8 получаем 220 TOPS, а INT4, которые еще не используются, уже 440 TOPS.
Основное использование ядер Tensor — это NVIDIA Neural Graphics Framework (NGX). NGX предоставляет интерфейсы для вычислений Deep Learning Super Sampling (DLSS) и различных эффектов постобработки через ANSEL. Но на этом мы остановимся чуть позже.
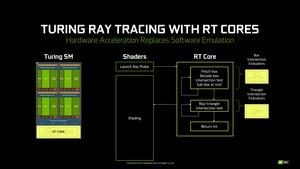
Ядра RT — это второй тип специальной аппаратной конструкции в архитектуре Тьюринга, которая используется впервые. Полная трассировка лучей отнимает слишком много времени и ресурсов даже при наличии тысяч потоковых процессоров на графический процессор. По этой причине NVIDIA добавила в архитектуру Turing ядра RT, которые выполняют необходимые вычисления для трассировки лучей. И некоторые типы вычислений очень эффективно обрабатываются ядрами RT. Все технологии трассировки лучей сегодня стараются снизить вычислительную нагрузку, для этого используют разные алгоритмы.
Все они основаны на том принципе, что удаленные от луча примитивы не могут с ним пересекаться. Поэтому рассчитывать их нет смысла. Экспоненциальный рост количества лучей приводит к тому, что для каждого луча нужно обрабатывать как можно меньше примитивов, чтобы не увеличивать вычислительную нагрузку.
Один из способов выбора примитивов — это иерархия ограничивающих объемов (BVH). В случае BVH сцена делится на меньшие и меньшие блоки, в которых присутствуют примитивы. Радиус должен обрабатываться только с теми блоками, которые он пересекает на пути к примитиву. Этот подход чем-то напоминает воксели, которые NVIDIA использует для Voxel Global Illumination (VXGI). BVH — это дерево, в котором вы можете увидеть, какой блок и, в конечном итоге, примитив следует учитывать при вычислениях трассировки лучей.
BVH на классических архитектурах GPU или на CPU может работать только в программном обеспечении. Следовательно, потоковые процессоры должны выполнять несколько тысяч инструкций на радиус, включая несколько циклов для поиска блоков и, в конечном итоге, один примитив. Только после нахождения примитива можно выполнять затенение лучей. Вот здесь и пригодятся ядра RT. Они содержат специальные функциональные блоки SFU (Special Function Unit), оптимизированные для поиска необходимых блоков и примитива, с которым пересекается луч. Потоковый процессор принимает действие, затем передает его в ядро RT, которое возвращает результат потоковому процессору, и потоковый процессор может выполнять рендеринг дальше по конвейеру.
Источники
- https://www.hardwareluxx.ru/index.php/artikel/hardware/grafikkarten/47517-faq-po-videokartam-geforce-chto-sleduet-znat-o-graficheskikh-kartakh.html?start=3